Vitess Blog
YouTube, Slack, GitHub에서 검증한 클라우드 네이티브 전문 DB – Vitess
Youtube, Slack, GitHub이 검증한 클라우드 네이티브 DB Vitess! 확장성과 안정성을 갖춘 현대적 데이터베이스 솔루션을 만나보세요.
2025년 01월 02일
개요
Vitess는 기존 MariaDB나 MySQL이 가진 한계를 극복하고, 초대형 트래픽과 데이터 처리를 위한 확장성과클라우드 네이티브 환경에서의 자동화 및 효율성을 제공합니다.
Kubernetes와의 통합, 자동 장애 복구 및 업그레이드 지원 등에서 Vitess는 클라우드 네이티브 환경에 완벽히 최적화되어 있습니다.
Vitess는 YouTube, Slack, GitHub, Square, Pinterest 등 다양한 글로벌 기업에서 다음과 같은 이유로 채택되었습니다:
- 자동 샤딩: 데이터 분산과 균형 유지
- 트래픽 처리: 수억 QPS 이상 지원
- 고가용성: 자동 장애 복구와 페일오버
- 클라우드 네이티브 통합: Kubernetes에서 유연한 확장과 관리
이러한 사례들은 Vitess가 대규모 데이터베이스 관리와 확장에 있어 뛰어난 솔루션임을 보여줍니다.

주요 토픽
Vitess 아키텍처
Vitess는 MySQL 기반의 분산 데이터베이스 관리 시스템으로, 주로 대규모 트래픽을 처리해야 하는 환경(예: 클라우드, 대규모 애플리케이션)에 사용됩니다.
처음에는 YouTube에서 대규모 MySQL 워크로드를 처리하기 위해 개발되었고, 지금은 Cloud Native Computing Foundation(CNCF) 프로젝트로 관리됩니다.
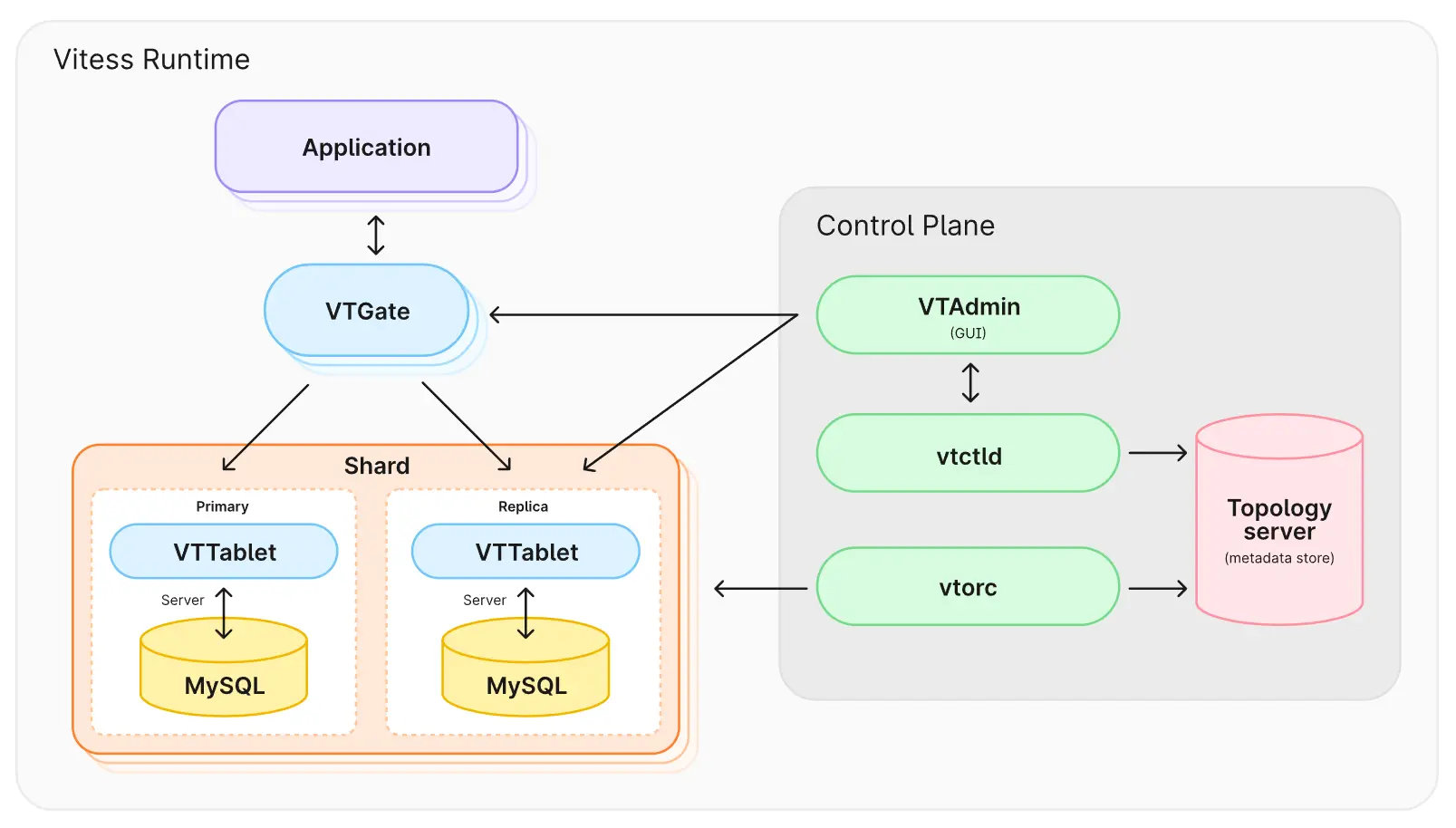
Vitess는 크게 데이터 처리 계층과 제어 계층으로 나뉩니다.
데이터 처리 계층
- VTGate:
- 데이터베이스 요청을 관리하고 라우팅하는 “게이트웨이” 역할을 합니다.
- 애플리케이션이 Vitess를 단일 데이터베이스처럼 사용할 수 있도록 합니다.
- 샤드가 여러 개여도 이를 감추고 필요한 샤드에 요청을 보냅니다.
- VTTablet:
- 각 샤드의 **Primary(쓰기)**와 Replica(읽기) 역할을 합니다.
- MySQL을 확장 가능한 형태로 활용할 수 있도록 관리합니다.
- 샤드 내부에서 데이터를 처리하는 핵심 구성 요소입니다.
- MySQL:
- 실제 데이터를 저장하는 기본 데이터베이스 엔진으로, Vitess가 MySQL 위에서 동작합니다.
제어 계층(Control Plane)
Vitess가 자동화와 관리 작업을 수행하도록 돕는 부분입니다.
- VTAdmin (GUI):
- Vitess를 관리할 수 있는 웹 기반 인터페이스입니다.
- 클러스터 상태 확인, 설정 변경 등을 수행할 수 있습니다.
- vtctld:
- Vitess의 중앙 관리 도구로, 클러스터 전체를 제어하고 관리합니다.
- 샤드 생성, 데이터 리샤딩 등 중요한 작업을 처리합니다.
- vtorc:
- 장애 복구 및 클러스터 복제 상태를 모니터링합니다.
- Primary 노드에 문제가 발생하면 자동으로 새로운 Primary를 설정합니다.
- Topology Server:
- 클러스터의 메타데이터를 저장하는 역할을 합니다.
- 샤드 정보, 노드 상태, 복제 구성을 저장하고, 전체 클러스터 상태를 공유합니다.
요청 흐름
- 애플리케이션이 데이터 요청을 하면, VTGate가 이를 받아 처리할 샤드를 결정합니다.
- VTGate는 적절한 VTTablet(Primary 또는 Replica)로 요청을 전달합니다.
- VTTablet은 MySQL 데이터베이스와 통신하여 데이터를 읽거나 씁니다.
- 모든 제어 작업은 제어 계층(Control Plane)에서 자동화 및 관리됩니다.
Vitess vs 기존 오픈소스 RDBMS 비교
Vitess는 기존 오픈소스 RDBMS와 비교해 대규모 확장성과 클라우드 환경 지원에서 압도적인 강점을 가집니다.
| 기능/특징 | 기존 오픈소스 RDBMS | Vitess |
|---|---|---|
| 확장성(Scalability) | 단일 인스턴스 확장 한계, 수동 샤딩 필요 | 자동 샤딩 및 수평 확장 가능 |
| 데이터 분산(Sharding) | 지원하지 않음 | 내장 샤딩 기능으로 데이터 자동 분산 |
| 트래픽 관리 | 읽기/쓰기 분리 가능하지만 수동 설정 필요 | 자동 읽기/쓰기 분리 및 로드 밸런싱 |
| 운영 관리(Automation) | 복제 및 장애 복구 수동 설정 | 자동화된 복제, 장애 복구 및 클러스터 관리 |
| 고가용성(High Availability) | 복제를 통해 가용성을 높일 수 있음 | 내장된 고가용성 관리로 빠른 장애 복구 지원 |
| 분산 트랜잭션 | 단일 인스턴스에서만 트랜잭션 처리 가능 | 여러 샤드에 걸친 분산 트랜잭션 지원 |
| 클라우드 네이티브 지원 | 제한적 또는 별도 도구 필요 | Kubernetes와 완벽 통합, 클라우드 환경 최적화 |
| 애플리케이션 호환성 | MySQL/MariaDB와 완벽 호환 | MySQL 프로토콜과 호환, 애플리케이션 변경 없이 사용 가능 |
| 성능 최적화 | 수동으로 튜닝 필요 | 쿼리 라우팅 및 캐싱으로 성능 자동 최적화 |
| 사용 사례 | 소규모 또는 단일 데이터베이스 환경에 적합 | 대규모 트래픽 처리, 클라우드 환경, 멀티 테넌트 시스템에 적합 |
| 복잡성 | 상대적으로 단순 | 클러스터 관리가 추가되나 자동화로 단순화 |
클라우드 네이티브 RDBMS Vitess 와 MariaDB, MySQL 비교
Kubernetes와의 통합, 자동 장애 복구 및 업그레이드 지원 등에서 Vitess는 클라우드 네이티브 환경에 완벽히 최적화되어 있습니다.
| 특징 | MariaDB/MySQL | Vitess |
|---|---|---|
| Kubernetes 통합 | 컨테이너 환경에서 실행 가능하지만 설정 및 관리 수동 필요 | 네이티브 통합: Kubernetes에서 자동 배포 및 관리 |
| 자동 확장(Auto Scaling) | 지원하지 않음 | 트래픽에 따라 샤드와 리플리카 자동 확장 |
| 장애 복구(Failover) | 수동 페일오버 설정 필요 | 자동 장애 복구: 다운타임 없이 마스터 전환 가능 |
| 업그레이드 | 업그레이드 중 서비스 다운타임 발생 가능 | 롤링 업그레이드: 서비스 중단 없이 클러스터 업그레이드 |
| 멀티 클라우드 지원 | 클라우드 환경 간 설정 복잡 | 멀티 클라우드 및 하이브리드 클라우드 지원 |
| 클러스터 관리 | 복제 및 클러스터 관리는 수동 작업 필요 | 자동화된 클러스터 관리: Kubernetes와 통합으로 운영 효율성 증대 |
Vitess – 클라우드를 위한 대규모 확장성(Massive Scalability) 제공
Vitess는 자동화된 샤딩과 수평 확장을 통해 대규모 트래픽과 데이터 관리에서 기존 MariaDB/MySQL 대비 훨씬 더 높은 확장성과 효율성을 제공합니다.
| 특징 | MariaDB/MySQL | Vitess |
|---|---|---|
| 확장성 | 단일 인스턴스 기반, 수직 확장(Scale-up) 위주 | 샤딩 기반 수평 확장(Scale-out) 가능 |
| 샤딩(Sharding) | 애플리케이션 레벨에서 수동으로 구현 필요 | 내장 샤딩 지원: 자동 데이터 분산 및 실시간 리샤딩 가능 |
| 읽기/쓰기 분리 | 읽기 전용 트래픽은 복제를 통해 분산 가능, 쓰기 트래픽은 제한적 | 읽기/쓰기 트래픽 자동 분리 및 로드 밸런싱 |
| 트래픽 처리량 | 최대 수백만 QPS 수준 | 수억 QPS 이상 처리 가능 (Slack, YouTube 사례) |
| 데이터 분산 전략 | 개발자가 직접 샤딩 논리 및 분산 전략 관리 필요 | 자동화된 데이터 분산: 샤드 간 데이터 균형 유지와 관리 가능 |
| 운영 복잡성 | 복잡한 확장 및 관리 작업 수동 처리 | 운영 간소화: 확장, 샤딩, 장애 복구 자동화 |
Reference
YouTube
사용목적
- YouTube는 2011년에 MySQL 기반 데이터베이스에서 확장성과 성능 문제가 발생하자 Vitess를 도입했습니다.
- 주로 동영상 메타데이터 저장과 트래픽 관리를 위해 사용됩니다.
세부사례
- 트래픽처리
- 동영상 검색, 추천, 시청 기록 등 매초 수십만 QPS를 처리해야 했습니다.
- MySQL 단일 인스턴스의 수직 확장만으로는 이러한 트래픽을 감당할 수 없었습니다.
- 샤딩
- Vitess를 통해 데이터베이스를 수백 개의 샤드로 분산했습니다.
- 동영상 메타데이터를 사용자 지역과 동영상 ID 기준으로 샤딩해 데이터 균형과 읽기/쓰기 성능을 최적화했습니다.
Slack
사용목적
- Slack은 메시지 데이터 저장과 실시간 동기화를 위해 Vitess를 채택했습니다.
- 메시지 전송량이 매일 수십억 건에 달하며, 메시지 검색 속도와 정확성이 매우 중요했습니다.
세부사례
- 데이터 저장소 확장
- Slack은 MySQL로 시작했으나 사용자 증가와 데이터 폭증으로 인해 기존 데이터베이스로는 확장이 어려웠습니다.
- Vitess를 도입해 데이터베이스를 자동 샤딩하고, 쓰기 트래픽을 여러 샤드로 분산해 병목현상을 해소했습니다.
- 실시간 장애 복구
- Vitess의 자동 장애 복구 기능 덕분에 데이터베이스 노드 장애 발생 시 빠른 페일오버로 서비스 중단 없이 운영이 가능했습니다.
- 고성능 읽기/쓰기 분리
- 메시지 데이터를 읽기 리플리카로 분산해 읽기 성능을 극대화하고, 동시에 쓰기 트래픽도 효율적으로 처리했습니다.
GitHub
사용목적
- GitHub은 리포지토리 메타데이터와 사용자 데이터를 관리하기 위해 Vitess를 도입했습니다.
- 대규모 리포지토리와 고속 데이터 읽기/쓰기 요청을 효율적으로 처리해야 했습니다.
세부사례
- 샤딩과 트래픽 분산
- 리포지토리 데이터는 규모가 크고 사용 패턴이 다양했기 때문에 Vitess를 통해 사용자와 프로젝트별 샤딩 전략을 도입했습니다.
- 데이터 샤드 간 트래픽 균형을 유지해 성능 최적화를 이뤘습니다.
- 멀티 클라우드 지원
- GitHub은 Vitess를 멀티 클라우드 환경에 배포해 유연한 확장성을 확보했습니다.
- 각 데이터센터 간 데이터 복제를 자동화해 지역별 서비스 성능을 극대화했습니다.
- 데이터베이스 업그레이드
- Vitess의 롤링 업그레이드 기능을 통해 GitHub은 서비스 중단 없이 데이터베이스를 최신 상태로 유지했습니다.
Square
사용목적
- Square는 결제 데이터와 거래 기록을 저장하고 처리하기 위해 Vitess를 채택했습니다.
- 높은 보안성과 고가용성이 필요한 결제 시스템에서 Vitess를 성공적으로 활용했습니다.
세부사례
- 고가용성 구현
- 결제 시스템은 다운타임이 허용되지 않기 때문에 Vitess의 자동 장애 복구를 통해 높은 가용성을 유지했습니다.
- 트랜잭션 중단 없이 장애 노드에서 마스터 전환이 이루어졌습니다.
- 대규모 트랜잭션 처리
- 수천 개의 동시 트랜잭션을 처리하기 위해 Vitess의 읽기/쓰기 분리와 분산 트랜잭션 기능을 활용했습니다.
- 클라우드 기반 운영
- Square는 Vitess를 클라우드 인프라에 배포해 거래 데이터와 결제 기록을 안정적으로 관리했습니다.
사용목적
- Pinterest는 사용자 데이터와 추천 알고리즘 결과를 저장하고 처리하기 위해 Vitess를 사용했습니다.
세부사례
- 대규모 읽기 트래픽 처리
- Vitess는 Pinterest에서 사용자 프로필과 핀 데이터를 읽기 리플리카로 분산해 초당 수백만 건의 읽기 요청을 처리했습니다.
- 유연한 확장
- 사용자 증가에 따라 샤드와 리플리카를 동적으로 추가해 데이터베이스 확장을 효율적으로 수행했습니다.
- 지연 시간 최소화
- Vitess는 지역별 데이터베이스 복제본을 통해 사용자 요청의 지연 시간을 최소화했습니다.
마무리
Vitess는 대규모 서비스와 클라우드 기반 인프라를 운영하려는 환경에서 MariaDB/MySQL보다 우수한 선택지로 평가받고 있습니다.
References & Related Links
- Vitess 공식 웹사이트: Vitess의 기능과 다른 데이터베이스와의 비교 정보를 제공합니다.
- 쿠버네티스 기반 데이터베이스 운영 #2 – Vitess 소개편: Vitess의 특징과 MySQL과의 비교를 다룬 블로그 글입니다.
- 플래닛스케일 리뷰: 수평 확장 가능한 마이SQL 호환 서버리스 DB: Vitess 기반의 데이터베이스 서비스인 PlanetScale에 대한 리뷰로, MySQL과의 비교를 포함하고 있습니다.
- Citus: Postgres 분산 데이터베이스 A-Z 소개: PostgreSQL 기반의 분산 데이터베이스인 Citus에 대한 소개로, Vitess와의 비교에 참고할 수 있습니다.- Medium
- Figma 데이터베이스 팀이 100배 규모 확장을 견뎌낸 방법: Figma의 데이터베이스 확장 사례를 다룬 글로, 다양한 오픈소스 데이터베이스 솔루션과의 비교를 포함하고 있습니다.

")